April 15th, 2022: By Nathan Cornille and Victor Milewski
Critical Analysis of Deconfounded Pretraining to Improve Visio-Linguistic Models; Finding Structural Knowledge in Multimodal-BERT
Critical Analysis of Deconfounded Pretraining to Improve Visio-Linguistic Models; Finding Structural Knowledge in Multimodal-BERT
Dynamic Key-value Memory Enhanced Multi-step Graph Reasoning for Knowledge-based Visual Question Answering; Zero-Shot Recommendations as Language Modeling
Revisiting spatio-temporal layouts for compositional action recognition; Predicting Physical World Destinations for Commands Given to Self-Driving Cars
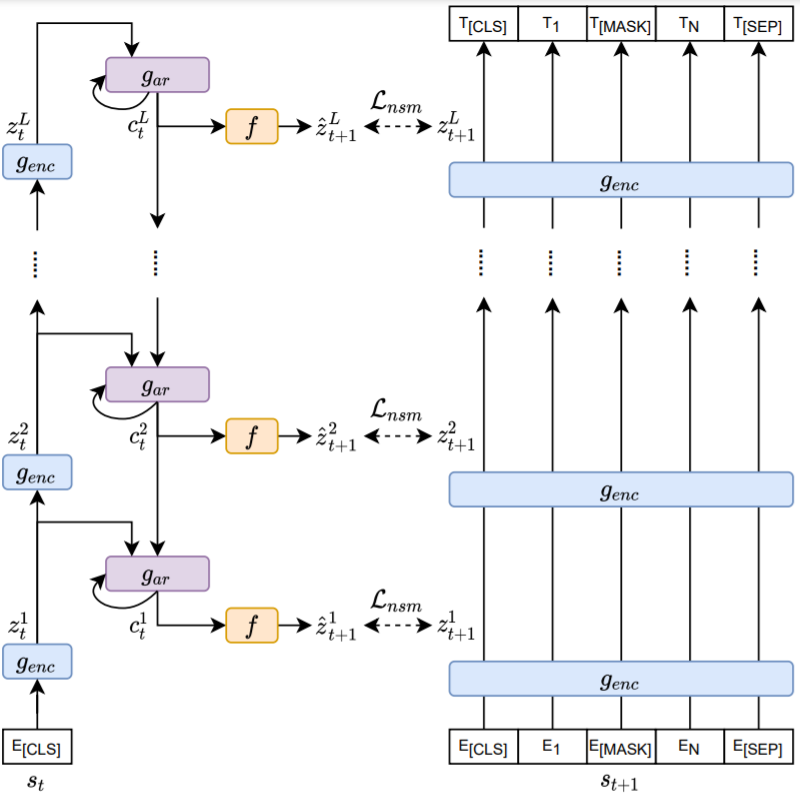
Augmenting BERT-style Models with Predictive Coding to Improve Discourse-Level Representations
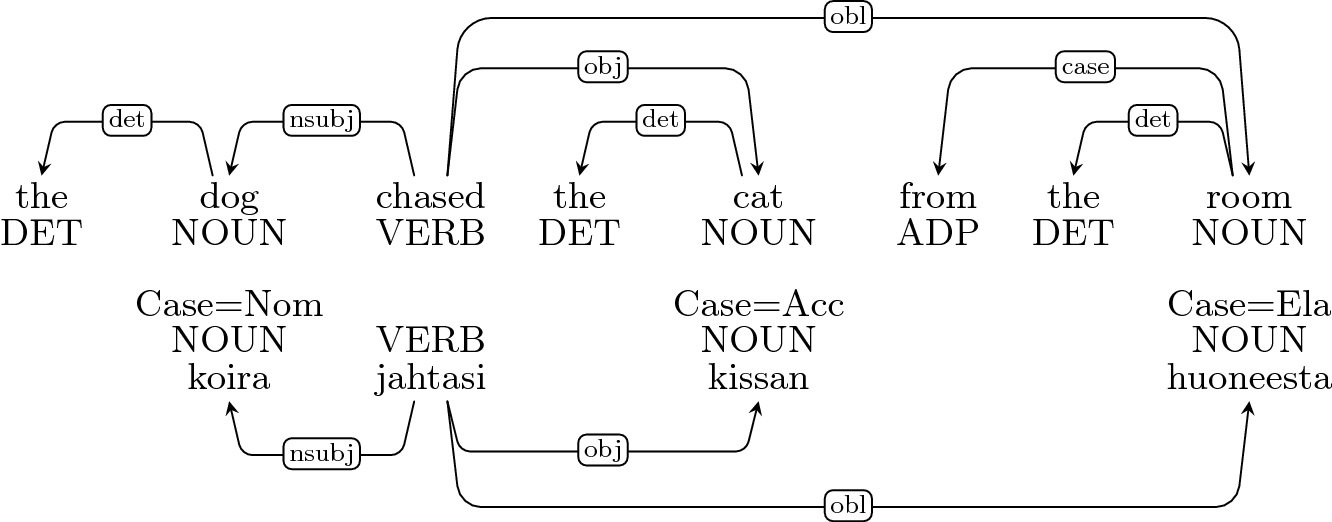
Imposing Relation Structure in Language-Model Embeddings Using Contrastive Learning; Discrete and Continuous Representations and Processing in Deep Learning
Time-Aware Evidence Ranking for Fact-Checking by Liesbeth Allein
Multilingual NLP and Interpretability by Miryam and Multimodal Face Naming by Tingyu
Problems and solutions for talking to self-driving cars by Thierry, and progress regarding Intelligent Automation for AI-driven Document Understanding by Jor...
Modeling Coreference Relations in Visual Dialog by Mingxiao Li, and a guest talk by dr. Bertrand De Longueville & dr. Alexandra Balahur
Multilingual Representation Learning by Erfan Gadry, and ecoding Language Spatial Relations to 2D Spatial Arrangements by Gorjan Radevski
Convolutional Generation of Textured 3D Meshes by Graham Spinks, and a guest talk by dr Iacer Calixto
Feedback and tips on using brain-inspired anticipation in Transformers, by Nathan and Are scene graphs good enough for image captioning, by Victor
In-depth review about Checkworthiness, by Liesbeth and how to leverage BERT models to generate speech features holding semantic information, by Quentin.